Character level language model - Dinosaurus Island¶
Welcome to Dinosaurus Island! 65 million years ago, dinosaurs existed, and in this assignment they are back. You are in charge of a special task. Leading biology researchers are creating new breeds of dinosaurs and bringing them to life on earth, and your job is to give names to these dinosaurs. If a dinosaur does not like its name, it might go berserk, so choose wisely!

|
Luckily you have learned some deep learning and you will use it to save the day. Your assistant has collected a list of all the dinosaur names they could find, and compiled them into this dataset. (Feel free to take a look by clicking the previous link.) To create new dinosaur names, you will build a character level language model to generate new names. Your algorithm will learn the different name patterns, and randomly generate new names. Hopefully this algorithm will keep you and your team safe from the dinosaurs' wrath!
By completing this assignment you will learn:
- How to store text data for processing using an RNN
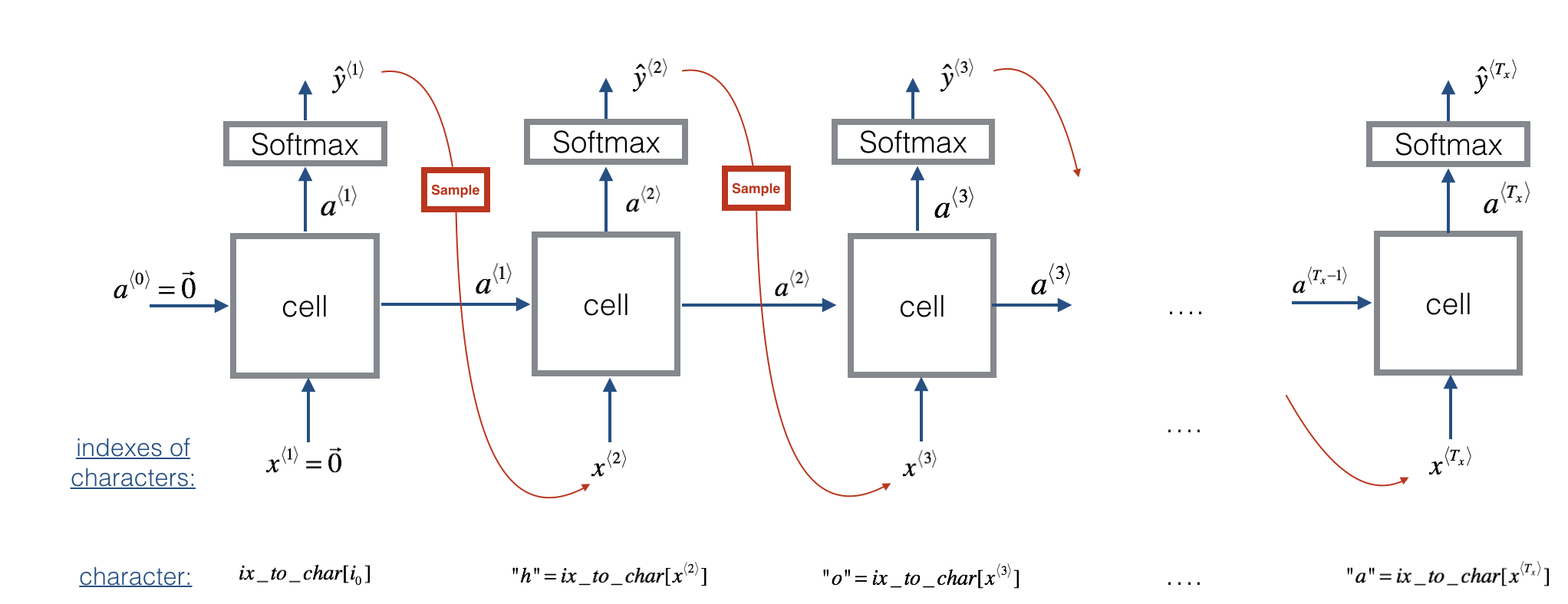
- How to synthesize data, by sampling predictions at each time step and passing it to the next RNN-cell unit
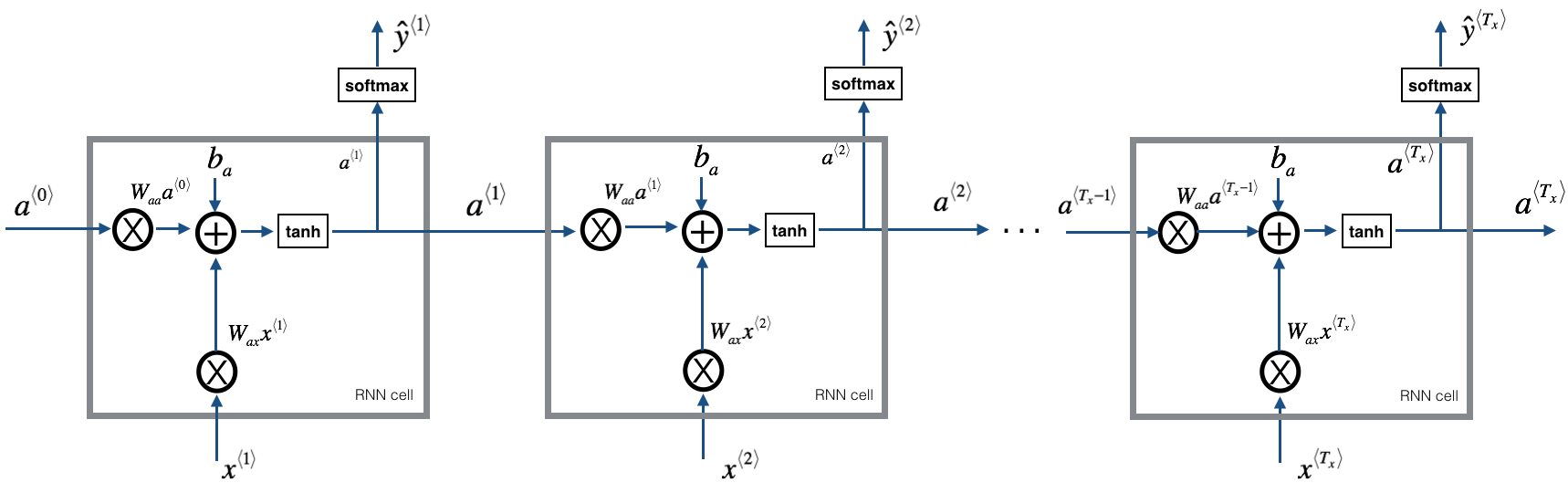
- How to build a character-level text generation recurrent neural network
- Why clipping the gradients is important
We will begin by loading in some functions that we have provided for you in rnn_utils. Specifically, you have access to functions such as rnn_forward and rnn_backward which are equivalent to those you've implemented in the previous assignment.